Big Data Patterns, Mechanisms > Data Maintenance Patterns > Centralized Dataset Governance
Centralized Dataset Governance (Buhler, Erl, Khattak)
How can a variety of datasets stored in a Big Data platform be governed efficiently and in a standardized manner?

Problem
Solution
Application
Mechanisms
A data governance manager is used to centralize data governance tasks. Through a graphical user interface, it allows viewing and searching metadata, which helps with dataset discovery and the retaining of a single copy of a dataset without creating duplicate copies. A lineage viewer provides the ability to view which data processing operations, such as queries, make use of the dataset and its constituent elements. The data governance manager centralizes the configuration of dataset access logging, such as what details should be recorded when a client tries to access a dataset and provides means for viewing dataset access log. For the enforcement of dataset policies, such as for how long a dataset should be kept and when the data should be archived, the data governance manager provides an interface for authoring policies that are then automatically executed generally through a workflow engine.
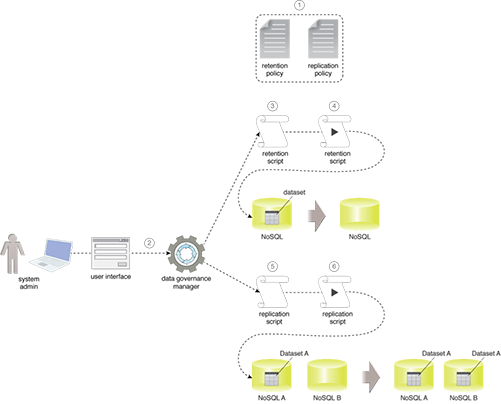
- A system administrator needs to implement two different data management policies: a retention policy that dictates that a dataset should only be retailed for 180 days and a replication policy that dictates that Dataset A needs to be copied from NoSQL A to NoSQL every 7 days.
- The system administrator uses the interface provided by the data governance manager to add retention policy and replication policy.
- The data governance manager automatically generates a retention script from the retention policy.
- The data governance manager automatically executes the retention script on the specified NoSQL database every 180 days to delete the dataset.
- The data governance manager automatically generates a replication script from the replication policy.
- The data governance manager then automatically executes the replication script every 7 days to copy Dataset A from NoSQL A to NoSQL B.
 Module 11: Advanced Big Data Architecture.")
This pattern is covered in BDSCP Module 11: Advanced Big Data Architecture.
For more information regarding the Big Data Science Certified Professional (BDSCP) curriculum,
visit www.arcitura.com/bdscp.

The official textbook for the BDSCP curriculum is:
Big Data Fundamentals: Concepts, Drivers & Techniques
by Paul Buhler, PhD, Thomas Erl, Wajid Khattak
(ISBN: 9780134291079, Paperback, 218 pages)
Please note that this textbook covers fundamental topics only and does not cover design patterns.
For more information about this book, visit www.arcitura.com/books.