Machine Learning Patterns, Mechanisms > Data Reduction Patterns > Feature Extraction
Feature Extraction (Khattak)
How can the number of features in a dataset be reduced so that the predictive potential of such features is on par with the filtered features?
Problem
In a bid to develop a simple model, dropping features from a dataset can potentially lead to a less effective model with poor accuracy.
Solution
Rather than filtering out the features, the majority or all features are kept and the predictive potential of all features is captured by deriving new features.
Application
A limited number of new features is generated by subjecting the dataset to feature extraction techniques such as Principal Component Analysis (PCA) and Singular Value Decomposition (SVD).
Mechanisms
Query Engine, Analytics Engine, Processing Engine, Resource Manager, Storage Device, Visualization Engine
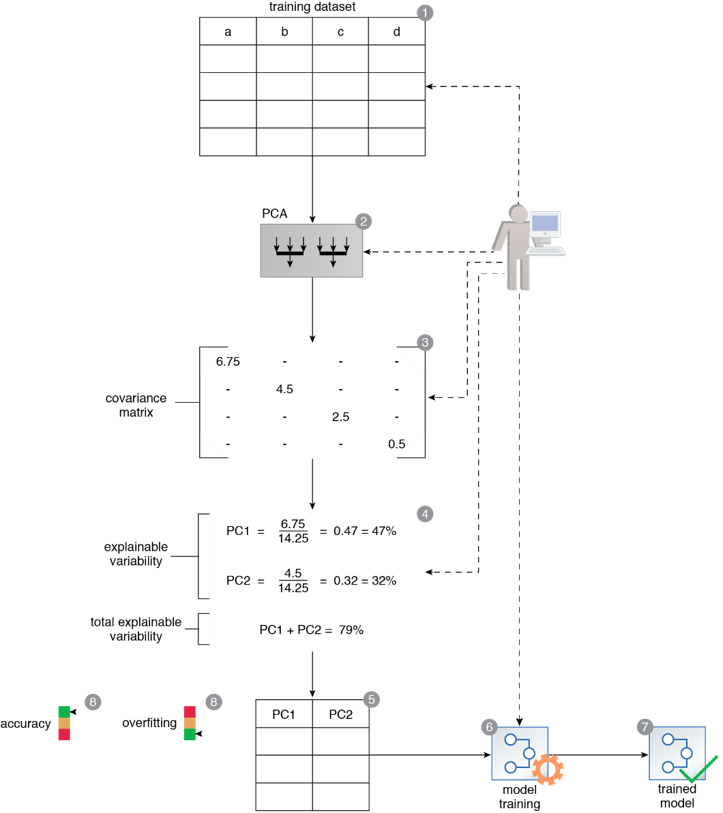
A training dataset is prepared (1). In order to keep the resulting model simple, the complete dataset is exposed to the PCA technique (2). This results in a matrix with Eigen values in diagonal from top-left to bottom-right (3). The explainable variability by each principal component obtained from the matrix is then calculated (4). Based on the results, principal components 1 and 2 are selected to meet the target of being able to explain at least 75% variability in the dataset (5). PC1 and PC2 values are then used to train a model (6, 7). The resulting model has increased accuracy and only suffers slightly from overfitting (8).
 Module 10: Fundamental Big Data Architecture")
This pattern is covered in Machine Learning Module 2: Advanced Machine Learning.
For more information regarding the Machine Learning Specialist curriculum, visit www.arcitura.com/machinelearning.