Machine Learning Patterns, Mechanisms > Model Optimization Patterns > Incremental Model Learning
Incremental Model Learning (Khattak)
How can a model be retrained without having to be trained from scratch when new data is acquired?
Problem
After the initial training of a model, it is imperative that the model is retrained as new data becomes available. However, this retraining can take a long time and can utilize excessive processing resources, thereby risking the availability of an up-to-date model in a timely fashion.
Solution
A classifier that is not dependent on historical data and only requires new data for retraining is deployed to make predictions.
Application
An incremental classifier such as Naïve Bayes is used where the model is updated based on new example data only without the need for regenerating the whole model from scratch.
Mechanisms
Query Engine, Analytics Engine, Processing Engine, Resource Manager, Resource Manager, Storage Device, Workflow Engine
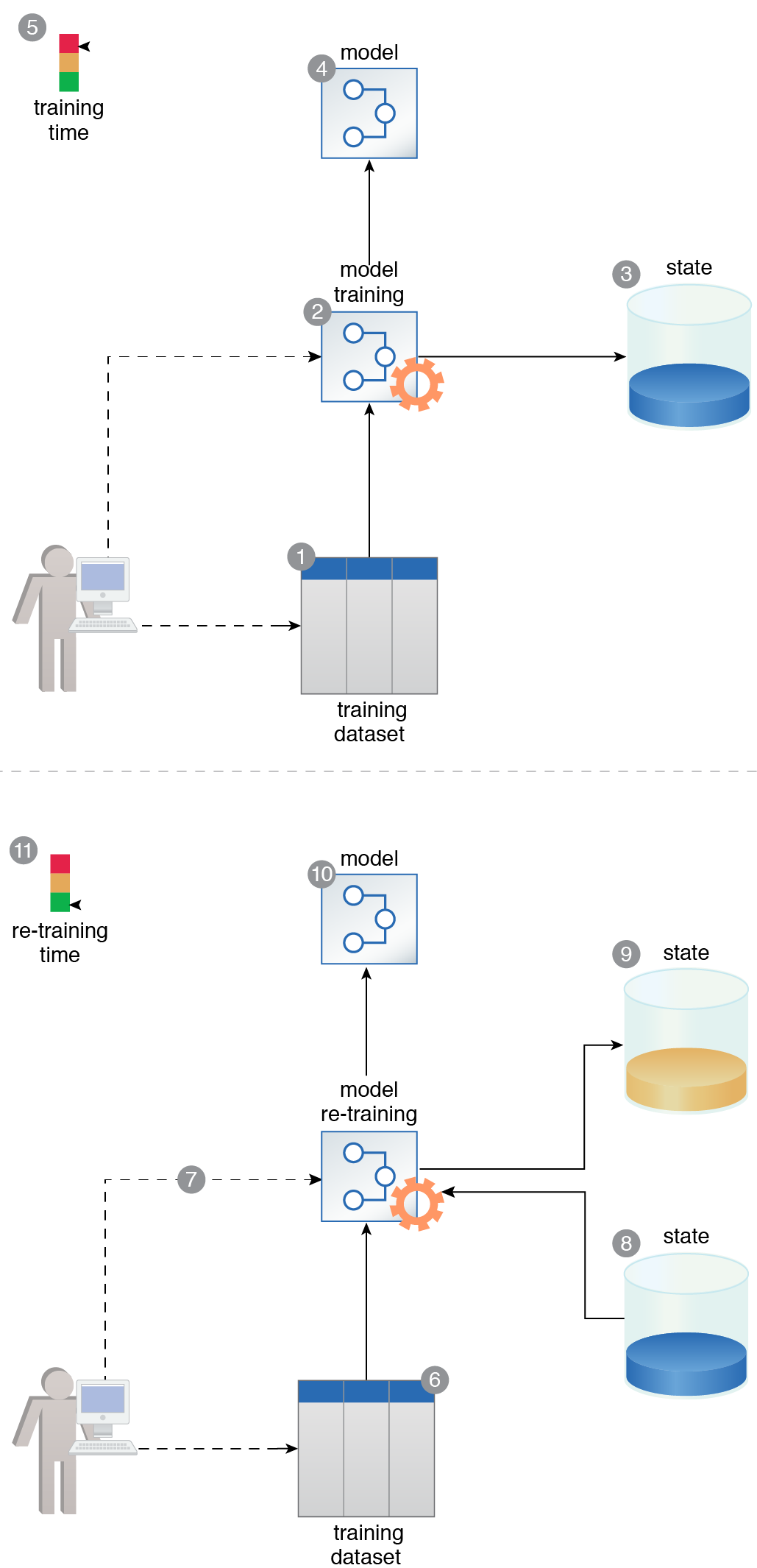
A training dataset is prepared (1). An incremental algorithm is used to train a model. Once it is trained, the model’s state is kept (2, 3, 4). The training process takes a long time to complete (5). After a certain period of time, another training dataset is prepared (6). The newly prepared dataset is then used to retrain the model (7). During the retraining process, the old state of the model is first retrieved (8). Once the training is complete, the updated state is saved (9) and results in a retrained model (10). The retraining process takes considerably less time to complete than the original training time (11).
 Module 10: Fundamental Big Data Architecture")
This pattern is covered in Machine Learning Module 2: Advanced Machine Learning.
For more information regarding the Machine Learning Specialist curriculum, visit www.arcitura.com/machinelearning.