Machine Learning Patterns, Mechanisms > Data Reduction Patterns > Feature Selection
Feature Selection (Khattak)
How can only the most relevant set of features be extracted from a dataset for model development?
Problem
Development of a simple yet effective machine learning model requires the ability to select only the features that carry the maximum prediction potential. However, when faced with a dataset comprising a large number of features, a trial-and-error approach leads to loss of time and processing resources.
Solution
The dataset is analyzed methodically and only a subset of features is kept for model selection, thereby keeping the model simple yet effective.
Application
Established feature selection techniques, such as forward selection, backward elimination and decision tree induction, are applied to the dataset to help filter out the features that do not significantly contribute towards building an effective yet simple model.
Mechanisms
Query Engine, Analytics Engine, Processing Engine, Resource Manager, Storage Device
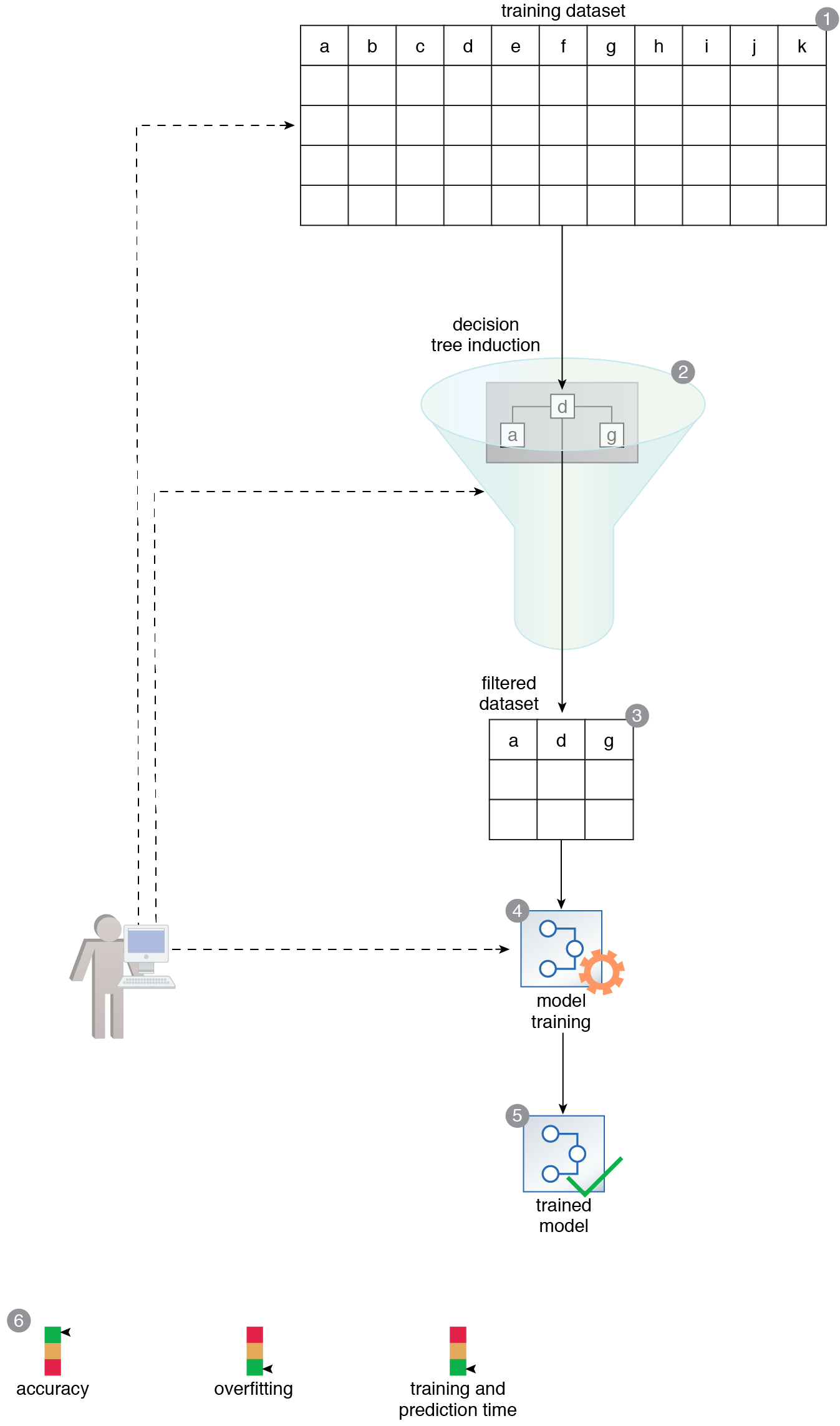
A dataset is prepared that consists of a large number of features (1). The analytics engine mechanism is used to assist with feature selection by exposing the dataset to the decision tree induction technique (2). This results in a subset of the original training dataset with only the most relevant features (3). This dataset is then used to train a new model (4, 5). The resulting model has increased accuracy, takes a shorter time to train and carry out predictions, and only slightly suffers from overfitting (6).
 Module 10: Fundamental Big Data Architecture")
This pattern is covered in Machine Learning Module 2: Advanced Machine Learning.
For more information regarding the Machine Learning Specialist curriculum, visit www.arcitura.com/machinelearning.