Machine Learning Patterns, Mechanisms > Model Evaluation Patterns > Training Performance Evaluation
Training Performance Evaluation (Khattak)
How can confidence be established in the efficacy of a machine learning model at training time?
Problem
A trained machine learning model may make predictions that are randomly correct or incorrect, or may make more incorrect predictions than correct ones. Productionalizing such a model can seriously jeopardize the effectiveness and reliability of a system.
OR
Different models can be developed to solve particular categories of a machine learning problems. However, not knowing which model works best may lead to choosing a not-so-optimum model for the production system with the further consequence of below-par system performance.
Solution
The model’s performance is quantified via established model evaluation techniques that make it possible to estimate the performance of a single model or to compare different models.
Application
Based on the type of machine learning problem, classification, clustering, and regression, various statistics and visualizations are generated including accuracy, confusion matrix, receiver operating characteristic (ROC) curve, cluster distortion, and means squared error (MSE).
Mechanisms
Query Engine, Analytics Engine, Processing Engine, Resource Manager, Storage Device, Visualization Engine
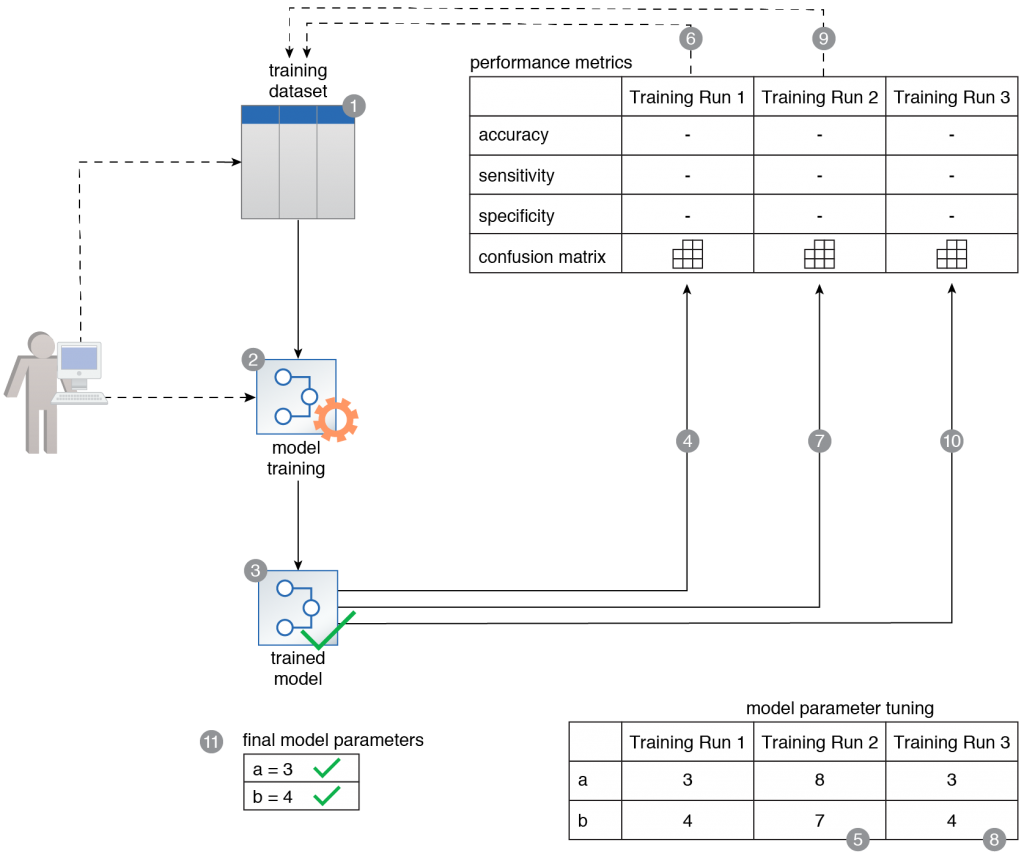
A training dataset is prepared (1). It is then used to train a binary classifier (2, 3). Various performance metrics are generated for each training run (4). Based on the results, the parameter values are retuned and the model is retrained (5, 6). The metrics are evaluated again, and the parameter values are once again retuned and the model is trained for a third time (7, 8, 9). After the third training run, the model is evaluated for one last time (10). After training the model three times, the performance of the model is satisfactory and the parameters used in the third training run are selected as the final values of the model parameters (11).
 Module 10: Fundamental Big Data Architecture")
This pattern is covered in Machine Learning Module 2: Advanced Machine Learning.
For more information regarding the Machine Learning Specialist curriculum, visit www.arcitura.com/machinelearning.