Service API Patterns, Protocols, Coupling Types, Metrics > Service API Design Patterns > Schema Centralization
Schema Centralization
How can service APIs be designed to avoid redundant schemas?
Different service APIs often need to process similar business documents or datasets, resulting in redundant schema content that is difficult to govern and keep synchronized.
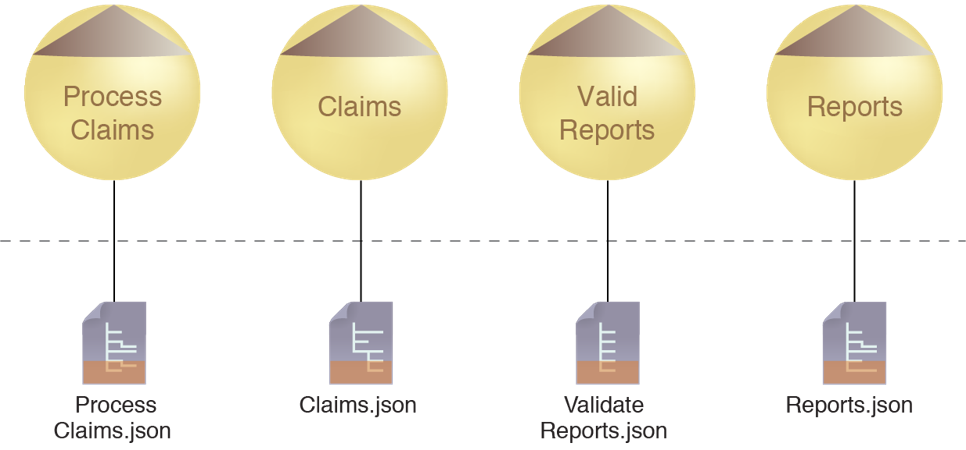
Four services use individual schemas that provide data models for similar datasets. As a result, redundancy exists across the schemas, as indicated by the shaded areas.
The application of the Schema Centralization pattern establishes data models that can exist independently from services so that they can be reused by service implementations. Schemas that represent commonly exchanged business documents are positioned as independent artifacts that can also be used by other parts of the surrounding solution or domain (outside of services). By refactoring the schemas, schema content redundancy can be reduced or eliminated.
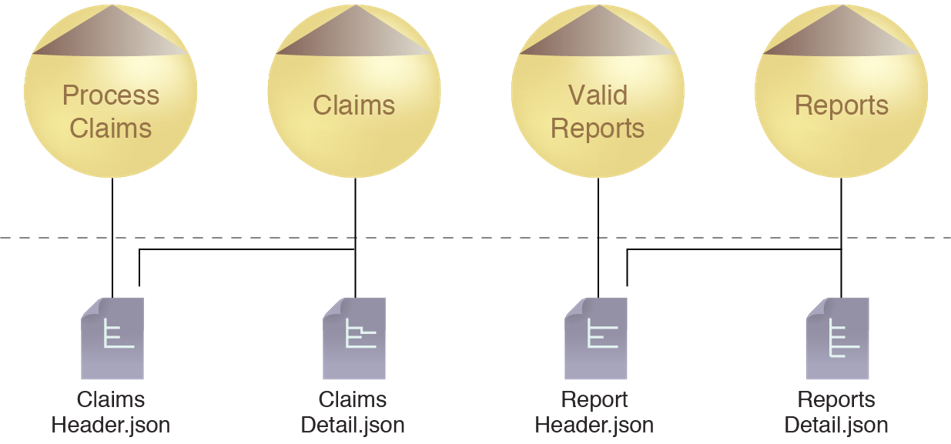
The services share common schemas that allow them to share the same message data models. The reduction of redundant schema content results in smaller-sized schemas.
 Module 10: Fundamental Big Data Architecture")
This pattern is covered in Module 13: Advanced Service API Design & Management.
For more information regarding service API design & management courses and accreditation, visit the Service API Specialist program page.