Cloud Computing Patterns, Mechanisms > Mechanisms > D - H > Failover System
Failover System

The failover system mechanism is used to increase the reliability and availability of IT resources by using established clustering technology to provide redundant implementations. A failover system is configured to automatically switch over to a redundant or standby IT resource instance whenever the currently active IT resource becomes unavailable.
Failover systems are commonly used for mission-critical programs or for reusable services that can introduce a single point of failure for multiple applications. A failover system can span more than one geographical region so that each location hosts one or more redundant implementations of the same IT resource.
This mechanism may rely on the resource replication mechanism to supply the redundant IT resource instances, which are actively monitored for the detection of errors and unavailability conditions.
Failover systems come in two basic configurations:
Active-Active
In an active-active configuration, redundant implementations of the IT resource actively serve the workload synchronously (Figure 1). Load balancing among active instances is required. When a failure is detected, the failed instance is removed from the load balancing scheduler (Figure 2). Whichever IT resource remains operational when a failure is detected takes over the processing (Figure 3).
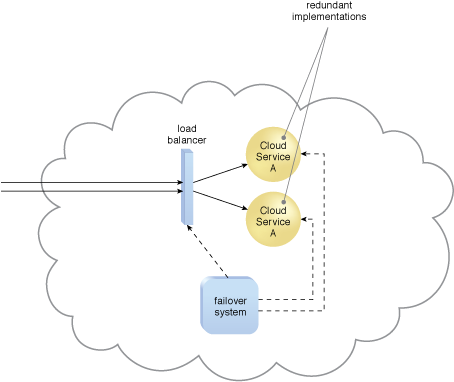
Figure 1 – The failover system monitors the operational status of Cloud Service A.
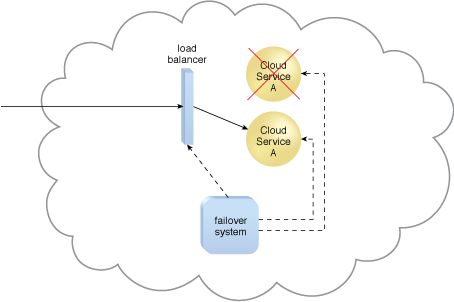
Figure 2 – When a failure is detected in one Cloud Service A implementation, the failover system commands the load balancer to switch over the workload to the redundant Cloud Service A implementation.
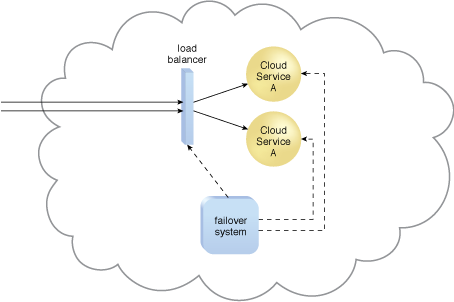
Figure 3 – The failed Cloud Service A implementation is recovered or replicated into an operational cloud service. The failover system now commands the load balancer to distribute the workload again.
Active-Passive
In an active-passive configuration, a standby or inactive implementation is activated to take over the processing from the IT resource that becomes unavailable, and the corresponding workload is redirected to the instance taking over the operation (Figures 4 to 5).
Some failover systems are designed to redirect workloads to active IT resources that rely on specialized load balancers that detect failure conditions and exclude failed IT resource instances from the workload distribution. This type of failover system is suitable for IT resources that do not require execution state management and provide stateless processing capabilities. In technology architectures that are typically based on clustering and virtualization technologies, the redundant or standby IT resource implementations are also required to share their state and execution context. A complex task that was executed on a failed IT resource can remain operational in one if its redundant implementations.
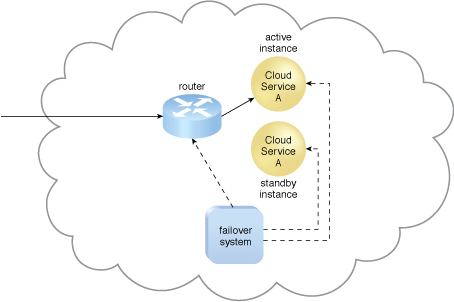
Figure 4 – The failover system monitors the operational status of Cloud Service A. The Cloud Service A implementation acting as the active instance is receiving cloud service consumer requests.
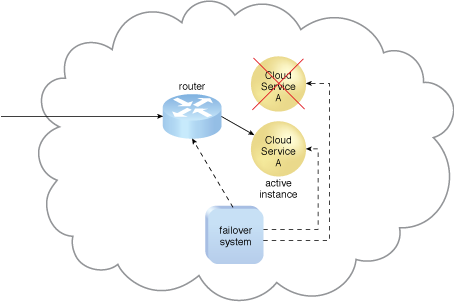
Figure 5 – The Cloud Service A implementation acting as the active instance encounters a failure that is detected by the failover system, which subsequently activates the inactive Cloud Service A implementation and redirects the workload toward it. The newly invoked Cloud Service A implementation now assumes the role of active instance.
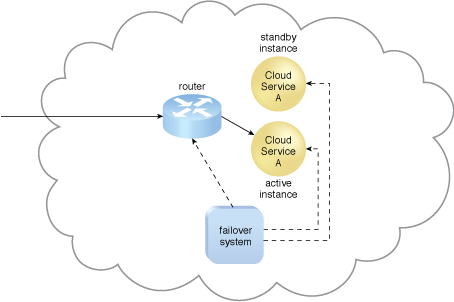
Figure 6 – The failed Cloud Service A implementation is recovered or replicated into an operational cloud service, and is now positioned as the standby instance, while the previously invoked Cloud Service A continues to serve as the active instance.
Related Patterns:
- Dynamic Failure Detection and Recovery
- Redundant Physical Connection for Virtual Servers
- Redundant Storage
- Storage Maintenance Window
- Synchronized Operating State
- Zero Downtime

This mechanism is covered in CCP Module 2: Cloud Technology Concepts.
For more information regarding the Cloud Certified Professional (CCP) curriculum, visit www.arcitura.com/ccp.

This cloud computing mechanism is covered in:
Cloud Computing: Concepts, Technology & Architecture by Thomas Erl, Zaigham Mahmood,
Ricardo Puttini
(ISBN: 9780133387520, Hardcover, 260+ Illustrations, 528 pages)
For more information about this book, visit www.arcitura.com/books.