Artificial Intelligence (AI) Patterns, Neurons and Neural Networks > Data Wrangling Patterns > Feature Imputation
Feature Imputation
How can a dataset with missing feature values be used for neural network development without having to delete entire rows or columns of valuable data?
Problem
One way to utilize a dataset containing missing values is to delete entire rows (instances) or columns (features) of data. However, this comes at the expense of losing valuable data that could have contributed towards developing a more accurate neural network.
Solution
Instead of deleting data, the missing feature values are inferred from the rest of the features through the application of statistical techniques or machine learning algorithms.
Application
Statistical techniques, such as mean, median, and mode, or machine learning algorithms, such as K-Nearest Neighbor (K-NN) and linear regression, are applied to the dataset to find the values of the missing fields.
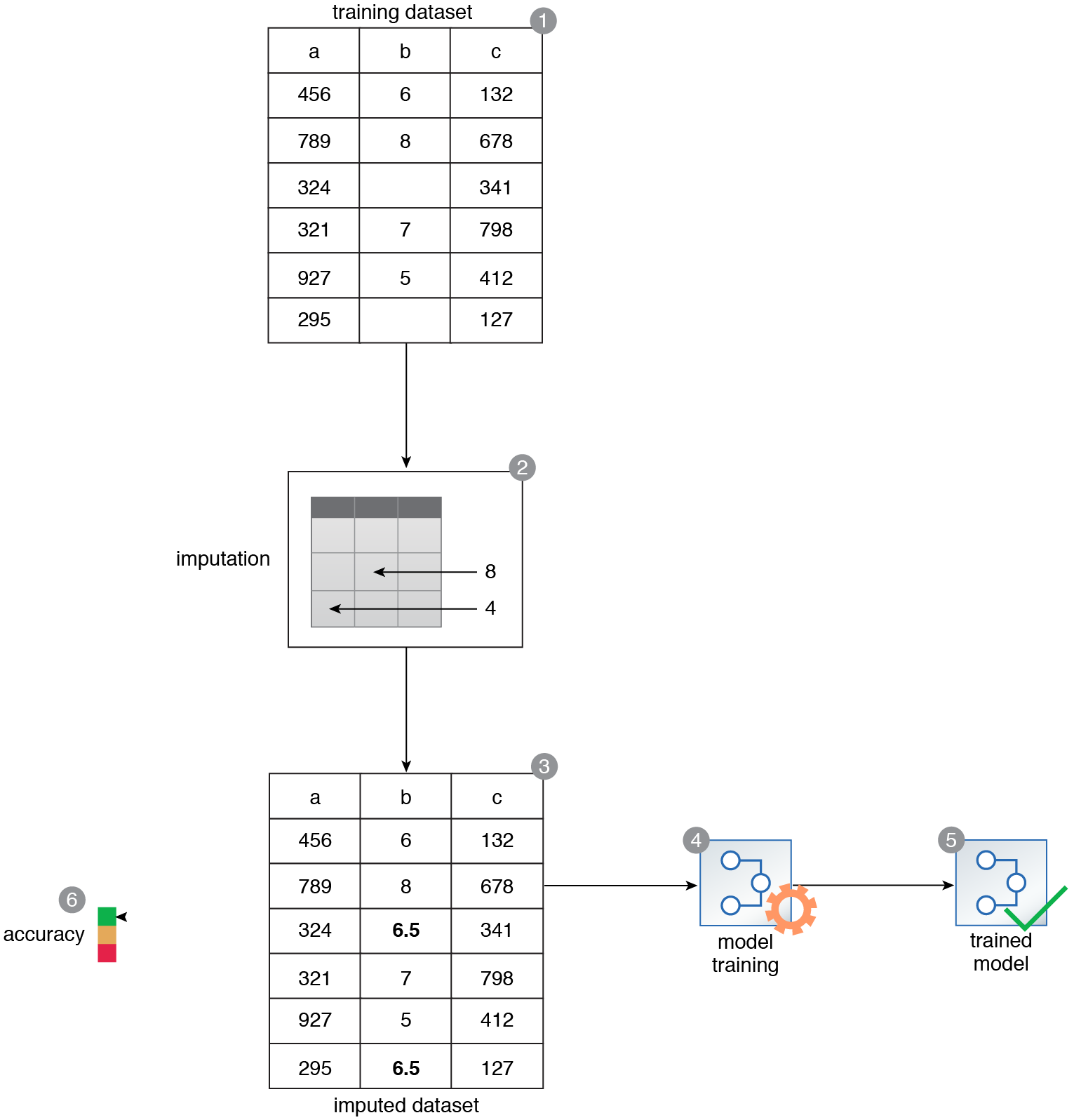
A data scientist prepares a training dataset that contains missing values for Feature B and cannot be used to train a neural network (1). The data scientist decides to apply the imputation technique in order to fill in the missing values (2). In the resulting dataset, the missing values for Feature B are imputed by using the mean value of Feature B (3). The imputed dataset is then used to train the neural network (4, 5). The resulting accuracy is within the expected range (6).
 Module 10: Fundamental Big Data Architecture")
This pattern is covered in Artificial Intelligence Module 2: Advanced Artificial Intelligence.
For more information regarding the Machine Learning Specialist curriculum, visit www.arcitura.com/artificialintelligence.