Machine Learning Patterns, Mechanisms > Model Optimization Patterns > Ensemble Learning
Ensemble Learning (Khattak)
How can the accuracy of a prediction task be increased when different prediction models provide varying levels of accuracy?
Problem
Developing different models either using the same algorithm with varied training data or using different algorithms with the same training data often results in varied level of model accuracy, which makes using a particular model less than optimal for solving a machine learning task.
Solution
Multiple models are built and leveraged by intelligently combining the results of the models in such a way that the resulting accuracy is higher than any individual model alone.
Application
Either homogeneous or heterogeneous models (for classification or regression) are developed. Techniques such as bagging, boosting, or random forests are then employed to create a meta-model.
Mechanisms
Query Engine, Analytics Engine, Processing Engine, Resource Manager, Storage Device
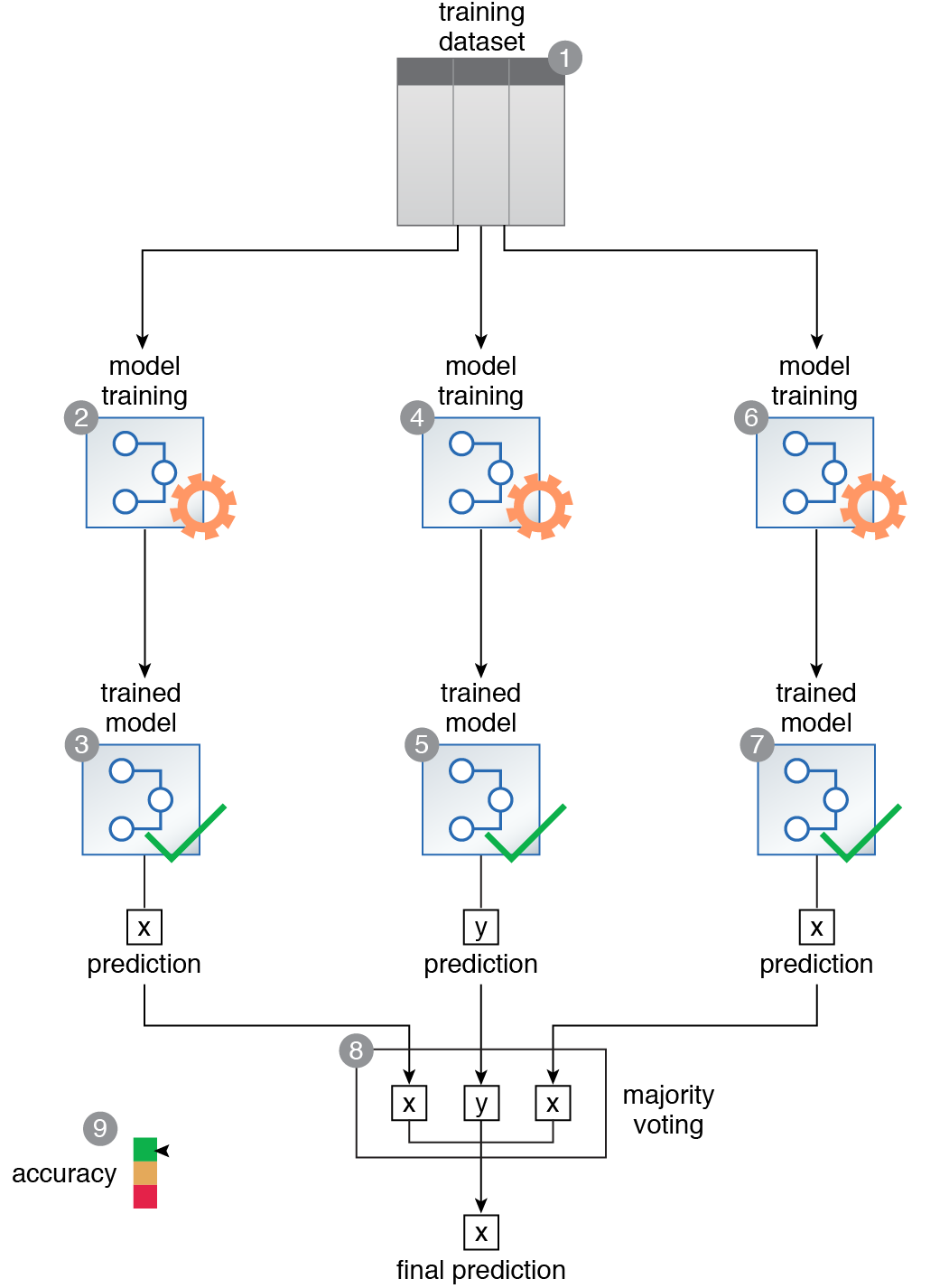
A training dataset is prepared to tackle a classification problem for the purpose of using an ensemble of classifiers to boost the overall accuracy (1). The K-NN algorithm is chosen to train the first model (2, 3). The Naïve Bayes algorithm is chosen to train the second model (4, 5). The decision trees algorithm is chosen to train the third model (6, 7). The prediction results from each model are then consolidated using the majority voting strategy (8). This results in a marked increase in the overall accuracy of the predictions (9).
 Module 10: Fundamental Big Data Architecture")
This pattern is covered in Machine Learning Module 2: Advanced Machine Learning.
For more information regarding the Machine Learning Specialist curriculum, visit www.arcitura.com/machinelearning.