Machine Learning Patterns, Mechanisms > Data Wrangling Patterns > Feature Standardization
Feature Standardization (Khattak)
How can it be ensured that features with wide-ranging values do not overshadow other features carrying a smaller range of values?
Problem
Features whose values exist over a wide scale carry the potential of reducing the predictive potential of features whose values exist over a narrow scale, thereby resulting in the development of a less accurate model.
Solution
All numerical features in a dataset are brought within the same scale so that the magnitude of each feature carries the same predictive potential.
Application
Statistical techniques, such as min-max scaling, mean normalization, and z-score standardization, are applied to convert the features’ values in such a way that the values always exist within a known set of upper and lower bounds.
Mechanisms
Query Engine, Analytics Engine, Processing Engine, Resource Manager, Storage Device
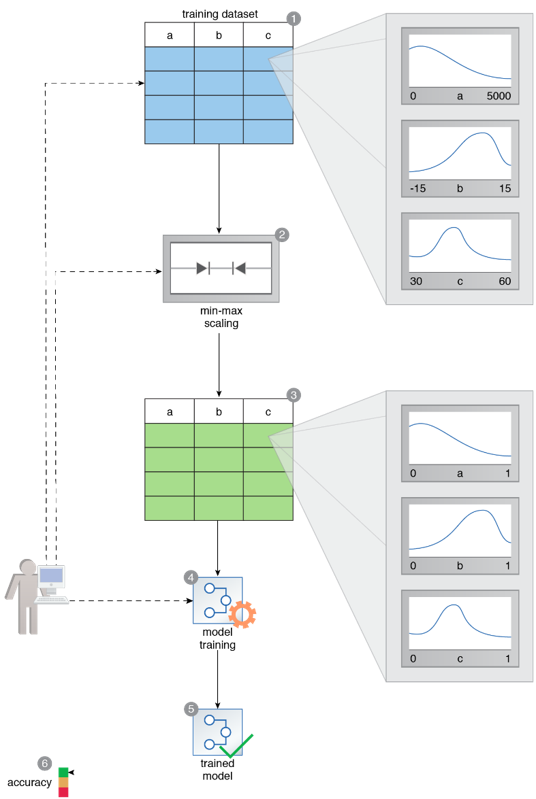
A training dataset comprises features with varying scales. Feature A’s values are between 0 and 5000, and Feature B’s values are between -15 and +15. Feature C’s values are between 30 and 60 (1). The dataset is exposed to the min-max scaling technique (2). The resulting standardized dataset contains values such that all feature values are now between 0 and 1 (3). The standardized dataset is then used to train a model (4, 5). The resulting model has very high accuracy (6).
 Module 10: Fundamental Big Data Architecture")
This pattern is covered in Machine Learning Module 2: Advanced Machine Learning.
For more information regarding the Machine Learning Specialist curriculum, visit www.arcitura.com/machinelearning.