Artificial Intelligence (AI) Patterns, Neurons and Neural Networks > Model Optimization Patterns > Overfitting Avoidance
Overfitting Avoidance
How can a neural network be trained so that it generalizes well to unseen data and maintains a level of accuracy that is comparable to training accuracy?
Problem
A neural network that performs too well on training data carries the potential of underperforming when tested on validation data or when productionalized, thereby resulting in a model that does not provide the expected results or business value.
Solution
The neural network is regularized by adding penalties to the loss function, controlling the training epochs, or by making some neurons inactive at random.
Application
For loss-based strategy, L1 or L2 regularization can be used. The training duration can be controlled by employing early stopping, and the random inactivation of neurons can be achieved via the dropout technique.
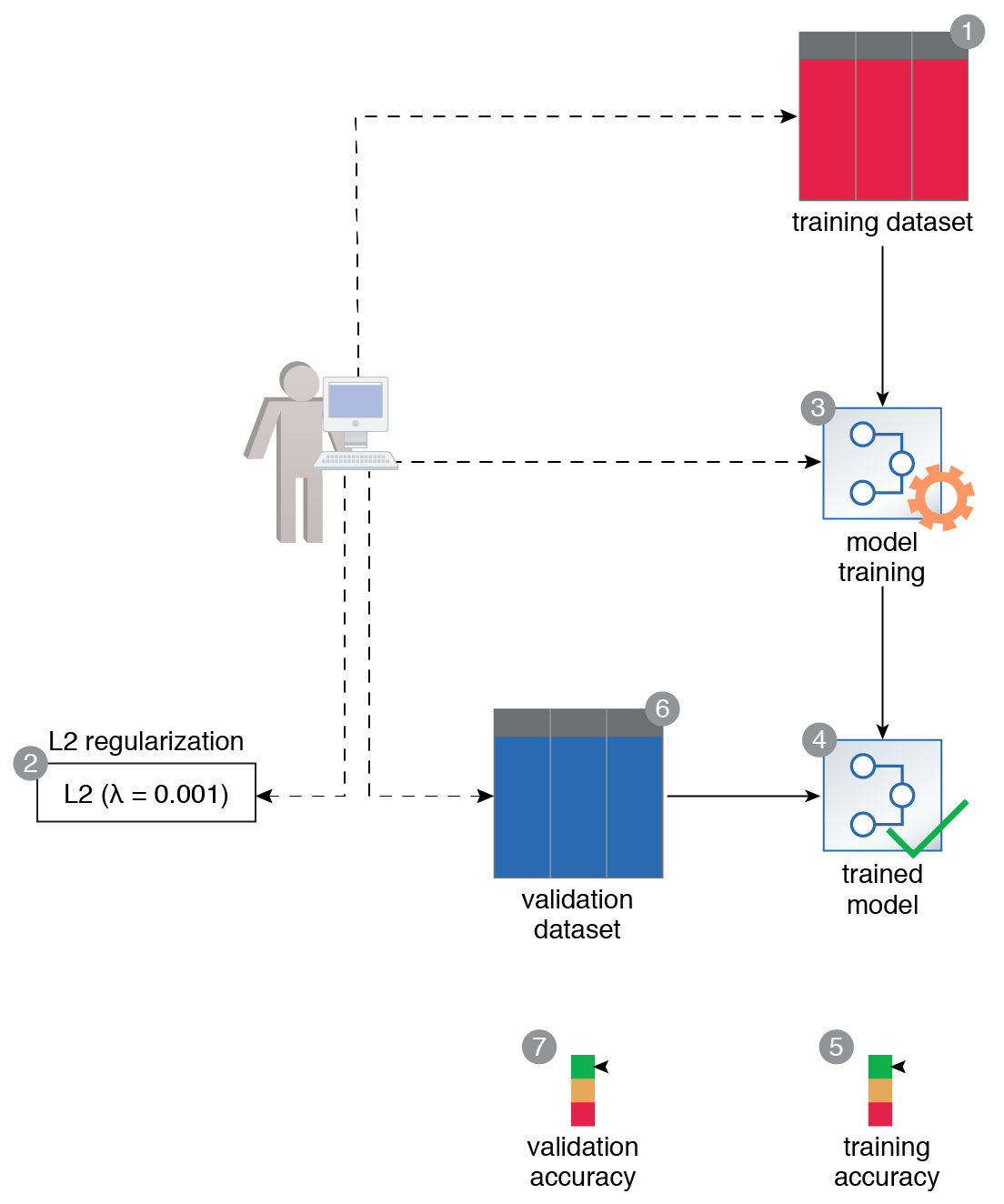
A data scientist prepares a dataset to train a neural network (1). Before training, while constructing the neural network, the data scientist applies L2 regularization by setting a value of 0.001 for the lambda hyperparameter (2). They then use the dataset to train the neural network (3, 4). After training, the network reports an accuracy score of 85% (5). When the network is evaluated against the validation data, the network’s accuracy comparatively remains the same at 82% (6, 7).
 Module 10: Fundamental Big Data Architecture")
This pattern is covered in Artificial Intelligence Module 2: Advanced Artificial Intelligence.
For more information regarding the Machine Learning Specialist curriculum, visit www.arcitura.com/artificialintelligence.