Machine Learning Patterns, Mechanisms > Data Wrangling Patterns > Feature Discretization
Feature Discretization (Khattak)
How can continuous features be used for model development when the underlying machine learning algorithm only supports discrete/nominal features?
OR
How can the range of values that a continuous feature can take on be reduced in order to lower model complexity?
Problem
Before solving a machine learning problem, a preliminary understanding of the input data is required. However, not knowing which techniques to start with can negatively impact the subsequent model development.
OR
Using numerical features with a very wide range of continuous values makes the model complicated with further implications of overfitting and longer training and prediction times.
Solution
A limited number of discrete sets of values are derived from continuous features by employing statistical or machine learning techniques.
Application
The continuous features are subjected to techniques such as binning and clustering that group continuous values into discrete bins, thereby discretizing continuous features into discrete ones.
Mechanisms
Query Engine, Analytics Engine, Processing Engine, Resource Manager, Storage Device
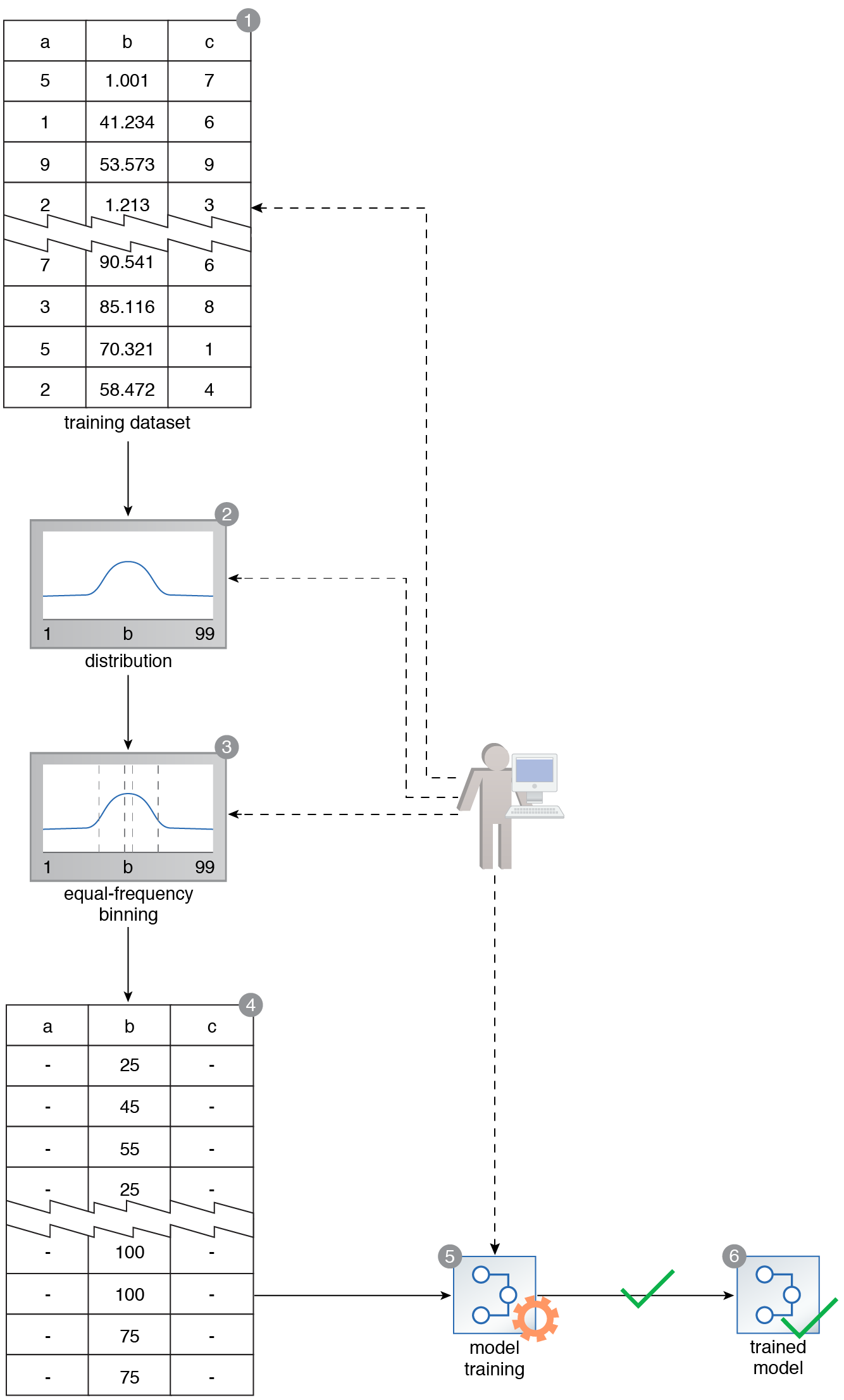
A training dataset contains Feature B, which consists of various values. A probabilistic model that works best with discrete values needs to be trained using this dataset (1). The binning technique is applied to Feature C. However, before a binning strategy is chosen, the distribution of Feature B is examined (2). It is determined that the distribution is normal, and the equal-frequency binning strategy is consequently applied (3). This results in a dataset where all feature values are discrete in nature (4). The model is then successfully trained using this dataset (5, 6).
 Module 10: Fundamental Big Data Architecture")
This pattern is covered in Machine Learning Module 2: Advanced Machine Learning.
For more information regarding the Machine Learning Specialist curriculum, visit www.arcitura.com/machinelearning.