Artificial Intelligence (AI) Patterns, Neurons and Neural Networks > Data Wrangling Patterns > Feature Scaling
Feature Scaling
How can it be ensured that a dataset with a wide range of features can be trained in a reasonable time period?
Problem
Features whose values exist over a wide scale negatively impact the loss reduction process of neural networks, resulting in longer training times and excessive use of processing resources.
Solution
All numerical features in a dataset are brought within the same scale such that the values are either between 0 and 1 or between -1 and +1.
Application
Statistical techniques, such as min-max scaling, mean normalization and z-score standardization, are applied that convert the feature values in such a way that the values always exist within a known set of upper and lower bounds.
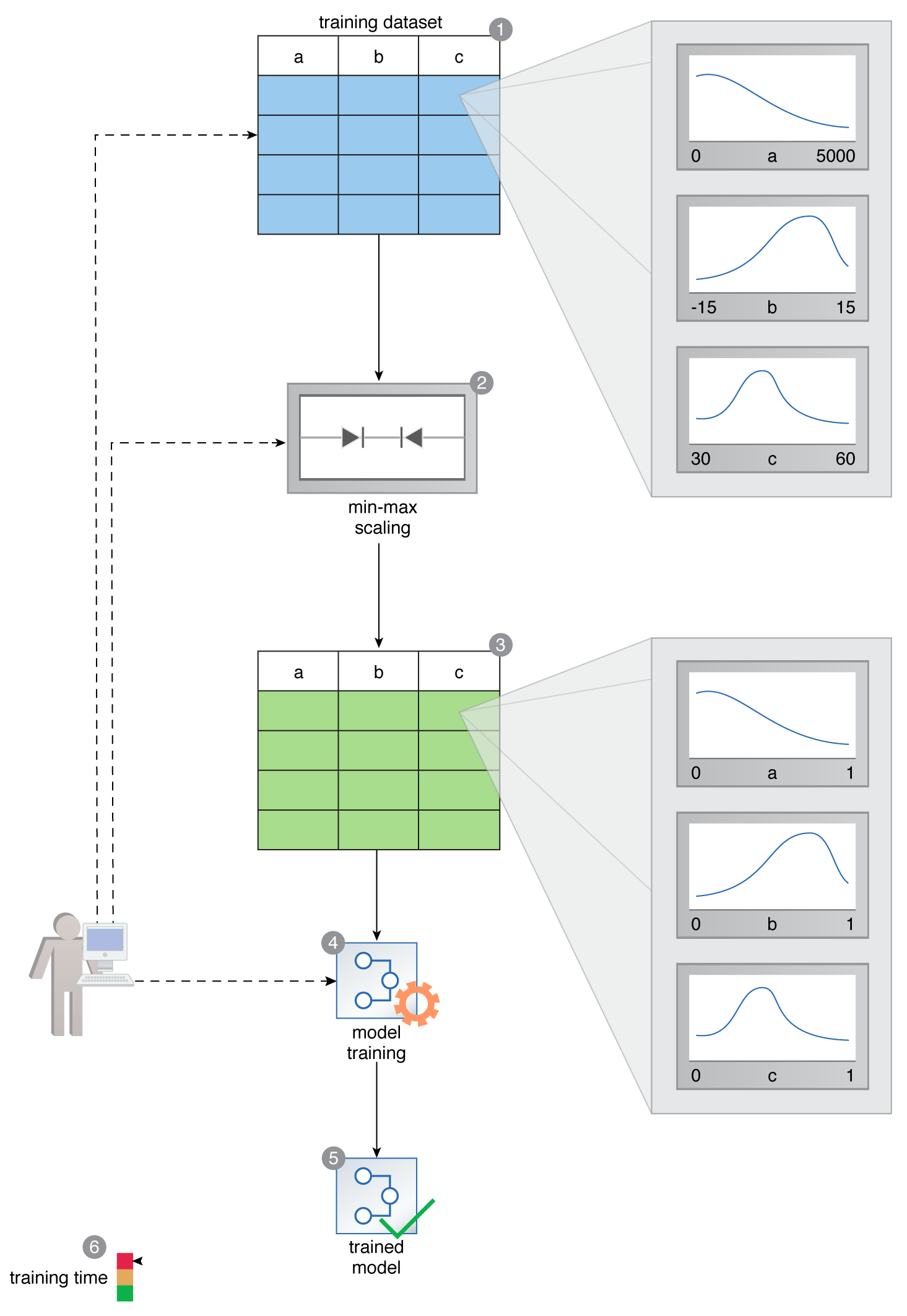
A data scientist prepares a training dataset that comprises features with varying scales. Feature A’s values are between 0 and 5000, Feature B’s values are between -15 and +15, and Feature C’s values are between 30 and 60 (1). The dataset is exposed to the min-max scaling technique (2). The resulting scaled dataset contains values such that all feature values are now between 0 and 1 (3). The scaled dataset is then used to train a neural network (4, 5). The network training process is completed in a shorter time period (6).
 Module 10: Fundamental Big Data Architecture")
This pattern is covered in Artificial Intelligence Module 2: Advanced Artificial Intelligence.
For more information regarding the Machine Learning Specialist curriculum, visit www.arcitura.com/artificialintelligence.