Machine Learning Patterns, Mechanisms > Unsupervised Learning Patterns > Pattern Discovery
Pattern Discovery (Khattak)
How can repeated sequences be found in large datasets comprised of a number of features without any previous examples of such sequences?
Problem
The discovery of naturally occurring groups within data is helpful with understanding the structure of the data. However, this does not help with finding meaningful repeating patterns within the data that can represent business opportunities or threats.
Solution
An associative model is developed that identifies patterns within the data in the form of rules, whereby the rules signify the relationship between data items.
Application
Associative rule learning algorithms, such as Apriori and Eclat, are employed to build an associative model that extracts rules (patterns) based on how frequently certain data items appear together.
Mechanisms
Query Engine, Analytics Engine, Processing Engine, Resource Manager, Storage Device
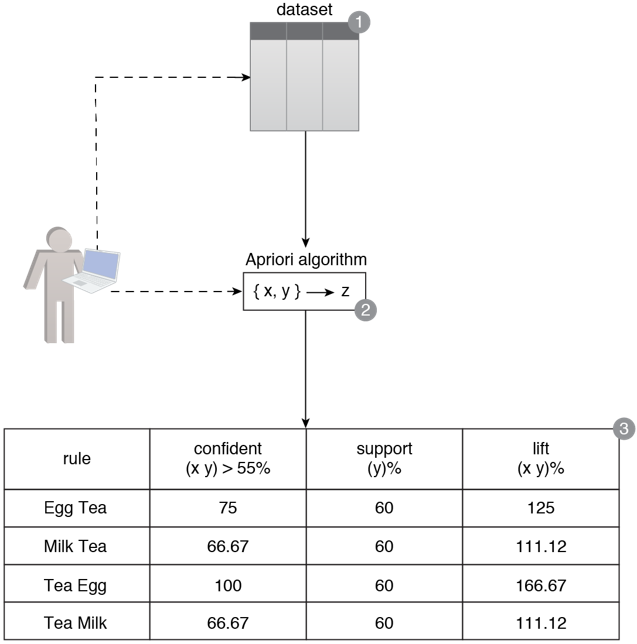
A list of common items that were frequently purchased together in the form of rules needs to be extracted so that when certain items are bought together, the changes of another product also being purchased increases (1). The Apriori algorithm is applied by setting thresholds for support and confidence equal to 45% and 55% respectively (2). This results in rules where the lift is above 100% for all rules. Based on this, it is concluded that the chances of buying eggs is the highest when tea is bought (3).
 Module 10: Fundamental Big Data Architecture")
This pattern is covered in Machine Learning Module 2: Advanced Machine Learning.
For more information regarding the Machine Learning Specialist curriculum, visit www.arcitura.com/machinelearning.