Cloud Computing Patterns, Mechanisms > Mechanisms > R - S > Resource Cluster
Resource Cluster

Cloud-based IT resources that are geographically diverse can be logically combined into groups to improve their allocation and use. The resource cluster mechanism is used to group multiple IT resource instances so that they can be operated as a single IT resource. This increases the combined computing capacity, load balancing, and availability of the clustered IT resources.
Resource cluster architectures rely on high-speed dedicated network connections, or cluster nodes, between IT resource instances to communicate about workload distribution, task scheduling, data sharing, and system synchronization. A cluster management platform that is running as distributed middleware in all of the cluster nodes is usually responsible for these activities. This platform implements a coordination function that allows distributed IT resources to appear as one IT resource, and also executes IT resources inside the cluster.
Common resource cluster types include:
- Server Cluster – Physical or virtual servers are clustered to increase performance and availability. Hypervisors running on different physical servers can be configured to share virtual server execution state (such as memory pages and processor register state) in order to establish clustered virtual servers. In such configurations, which usually require physical servers to have access to shared storage, virtual servers are able to live-migrate from one to another. In this process, the virtualization platform suspends the execution of a given virtual server at one physical server and resumes it on another physical server. The process is transparent to the virtual server operating system and can be used to increase scalability by live-migrating a virtual server that is running at an overloaded physical server to another physical server that has suitable capacity.
- Database Cluster – Designed to improve data availability, this high-availability resource cluster has a synchronization feature that maintains the consistency of data being stored at different storage devices used in the cluster. The redundant capacity is usually based on an active-active or active-passive failover system committed to maintaining the synchronization conditions.
- Large Dataset Cluster – Data partitioning and distribution is implemented so that the target datasets can be efficiently partitioned without compromising data integrity or computing accuracy. Each cluster node processes workloads without communicating with other nodes as much as in other cluster types.
Many resource clusters require cluster nodes to have almost identical computing capacity and characteristics in order to simplify the design of and maintain consistency within the resource cluster architecture. The cluster nodes in high-availability cluster architectures need to access and share common storage IT resources. This can require two layers of communication between the nodes—one for accessing the storage device and another to execute IT resource orchestration (Figure 1). Some resource clusters are designed with more loosely coupled IT resources that only require the network layer (Figure 2).
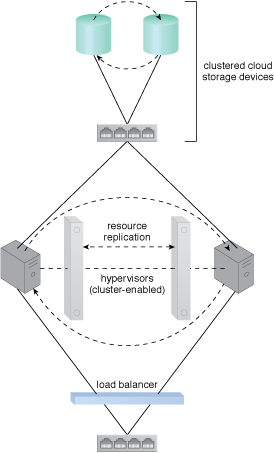
Figure 1 – Load balancing and resource replication are implemented through a cluster enabled hypervisor. A dedicated storage area network is used to connect the clustered storage and the clustered servers, which are able to share common cloud storage devices. This simplifies the storage replication process, which is independently carried out at the storage cluster.
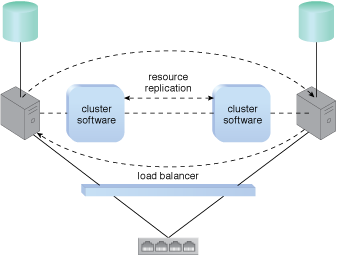
Figure 2 – A loosely coupled server cluster that incorporates a load balancer. There is no shared storage. Resource replication is used to replicate cloud storage devices through the network by the cluster software.
There are two basic types of resource clusters:
- Load Balanced Cluster – This resource cluster specializes in distributing workloads among cluster nodes to increase IT resource capacity while preserving the centralization of IT resource management. It usually implements a load balancer mechanism that is either embedded within the cluster management platform or set up as a separate IT resource.
- High-Availability (HA) Cluster – A high-availability cluster maintains system availability in the event of multiple node failures, and has redundant implementations of most of all of the clustered IT resources. It implements a failover system mechanism that monitors failure conditions and automatically redirects the workload away from any failed nodes.
The provisioning of clustered IT resources can be considerably more expensive than the provisioning of individual IT resources that have an equivalent computing capacity.
Related Patterns:
- Hypervisor Clustering
- Leader Node Election
- Load Balanced Virtual Server Instances
- Service Load Balancing
- Workload Distribution
- Zero Downtime

This mechanism is covered in CCP Module 4: Fundamental Cloud Architecture.
For more information regarding the Cloud Certified Professional (CCP) curriculum, visit www.arcitura.com/ccp.

This cloud computing mechanism is covered in:
Cloud Computing: Concepts, Technology & Architecture by Thomas Erl, Zaigham Mahmood,
Ricardo Puttini
(ISBN: 9780133387520, Hardcover, 260+ Illustrations, 528 pages)
For more information about this book, visit www.arcitura.com/books.